
One of the primary adoption drivers for serverless infrastructure is the promise to scale automatically on-demand into basically "infinite" compute power. On the one hand, this scaling allows you to perfectly serve sudden increases in usage. You're only charged for exactly what you use.
What could go wrong with basically infinitely scalable, on-demand infrastructure? It turns out, when used wrong, it leads to some alarming surprise bills like in this tweet:
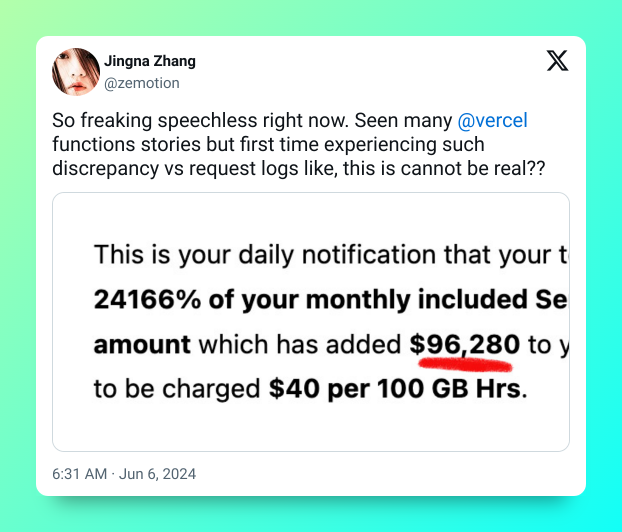
In short, they've received a massive bill for exceeding their included function execution amount. As it turns out, this was totally avoidable and is more of a usage than a Vercel issue, but we'll get to that in a second.
This certainly wasn't the only time function execution bills caused serious confusion, like in this tweet:
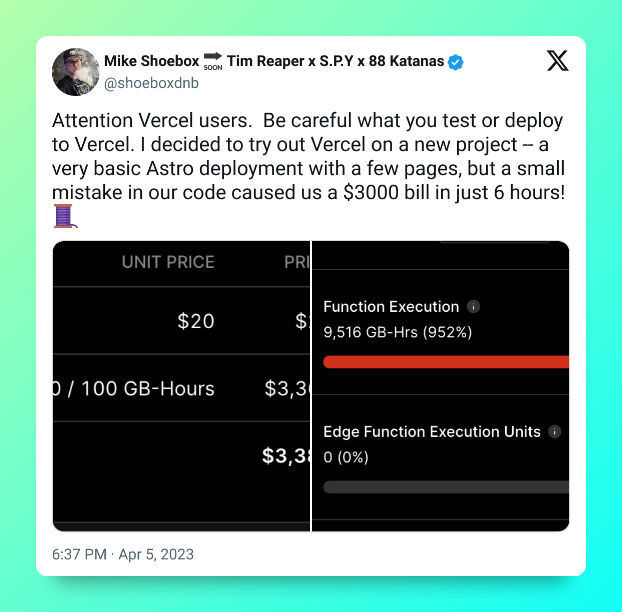
Or take this app going viral:
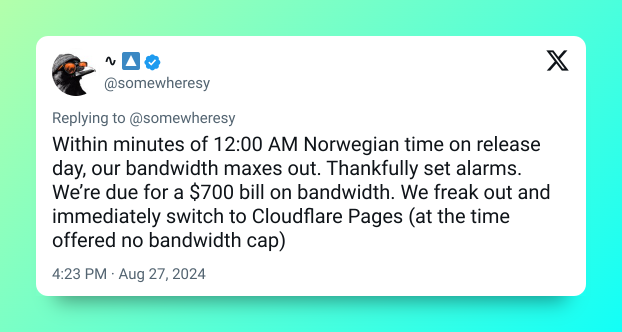
What's the problem?
Judging by the above horror cases, Vercel seems like a risky place for deployment, right?
Well, not really.
All of those cases were not only avoidable, but it also helps to understand that sudden, unexpected usage charges are rarely in the interest of the platform providing the services, either.
What's not immediately visible above is, for example, that one of these "totally unexpected" usage charges was the result of scaling up to 500.000 users basically overnight and not setting a spend limit, disregarding 12 prior emails and personal outreach from a Vercel rep to check in about these charges. Another surprise charge has received a complete bill waiver.
Now, even in the light of Vercel handling these cases well, it's best to avoid getting into such a situation in the first place. In this article, I'll show four ways to avoid receiving a surprise cloud bill.
Caching with Redis
Upstash's core product, Upstash Redis, is a performant key-value store that massively speeds up your app and reduces serverless costs by avoiding repeated database or API calls. The results are noticeably faster response times and lower costs.
Upstash Redis supports global replication for serving requests from the closest replica, reducing latency and costs for read-heavy applications. For more details on Redis caching and how it optimizes performance, check out this related blog article: Next.js Caching with Redis
Upstash Redis is accessible through both API and the official packages for Python and TypeScript. You can check out the documentation for more details.
Upstash Workflow
Upstash Workflow is a powerful tool for managing long-running business logic, which is typically difficult in serverless environments. It's built on top of Upstash's serverless messaging and scheduling solution, QStash, to support scheduling, automatic retries on failure, parallelism, and much more out of the box.
Here's a minimal code example of a durable, long-running serverless workflow:
import { serve } from "@upstash/qstash/nextjs"
export const POST = serve(async (context) => {
await context.run("step-1", async () => {
// process an image
})
// wait an hour
await context.sleep("step-2", 60 * 60)
await context.run("step-3", async () => {
// send a reminder email
})
})One of the most useful features of Upstash Workflow are long-running API calls.
In summary, you can offload any HTTP request and have it run for much longer than your serverless function timeout allows. You're not billed for any idle waiting time, and your code execution automatically resumes when the API response is ready.
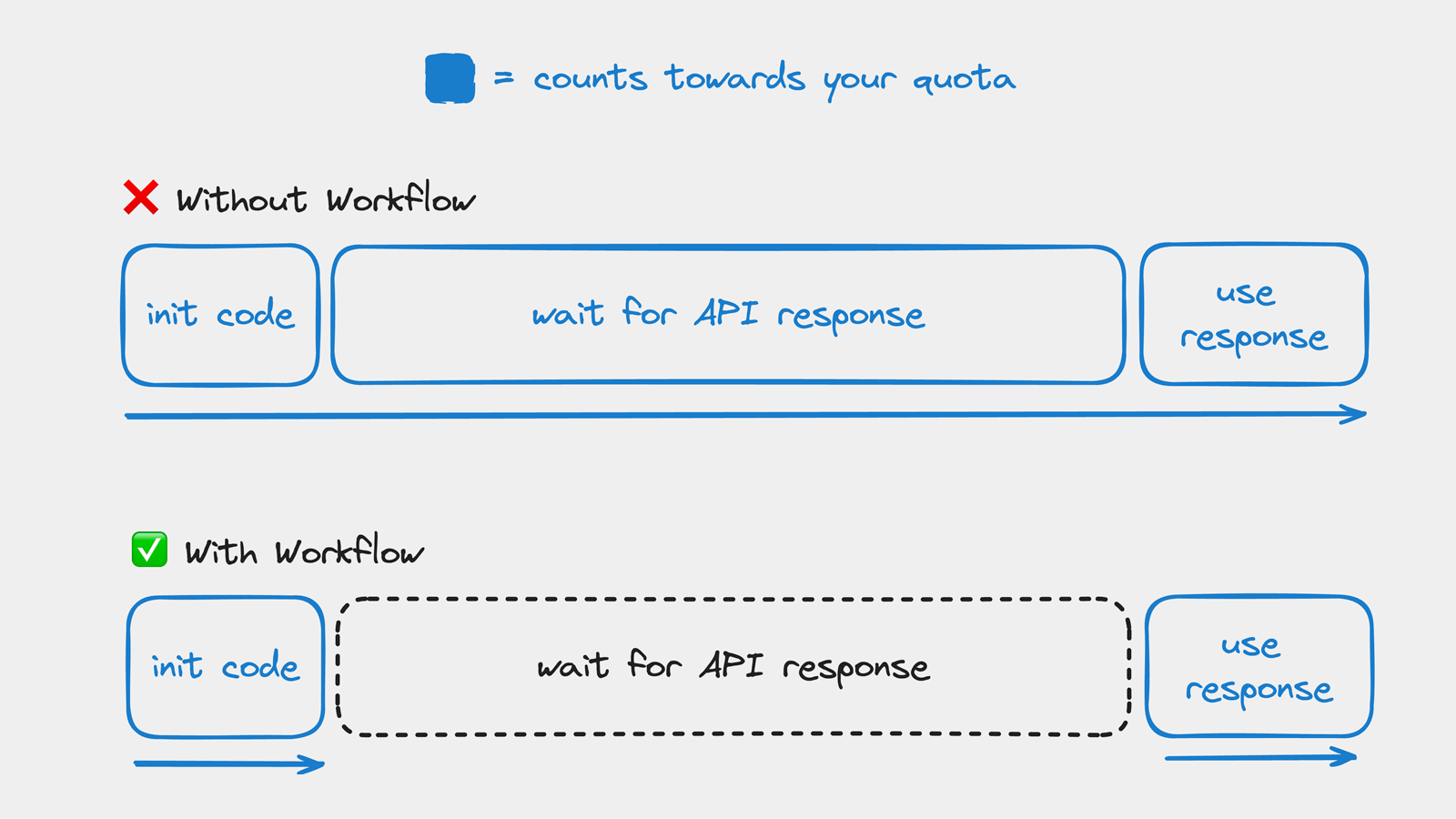
For more information on how this reduces serverless cost by up to 90%, check out our blog post: Get Rid of Function Timeouts and Reduce Vercel Costs.
Rate Limiting
Upstash Ratelimit is a tool for limiting the number of requests a specific IP address, userId, or a custom identifier can make to your services in a particular timeframe.
import { Ratelimit } from "@upstash/ratelimit";
import { Redis } from "@upstash/redis";
const ratelimit = new Ratelimit({
redis: Redis.fromEnv(),
limiter: Ratelimit.slidingWindow(10, "10 s"),
analytics: true,
});
// 👇 rate-limit by user IP
const { success } = await ratelimit.limit("127.0.0.1");
if (!success) {
return { error: "Too many requests. Please try again later."};
}
// ... actual request logicYou can enable analytics to monitor the usage from your dashboard:

In addition to basic rate limiting, the SDKs offer enhanced security features to protect your endpoints from attacks.
- By caching rate-limited identifiers, the client blocks requests without querying Redis, cutting costs and reducing latency especially during a DDOS attack.
- The traffic protection feature in the TypeScript SDK allows you to block specific IPs, countries, or other identifiers. You can also enable the Auto IP Deny List to automatically block malicious IP addresses from public deny lists.
Semantic Caching with Upstash Vector
If you're using LLMs in your apps, you're likely familiar with how expensive they can be in the long run. A great way to manage these expenses is using our semantic caching package (available in TypeScript and Python).
Here's the idea: Often, similar questions can be answered with the same response. By caching an AI response based on one user input, another question with similar user input (for example the same prompt, but phrased differently), can be answered from the cache, because the answer is the same. The answer will be both faster as it comes from the cache and cheaper as no separate AI round trip is needed.
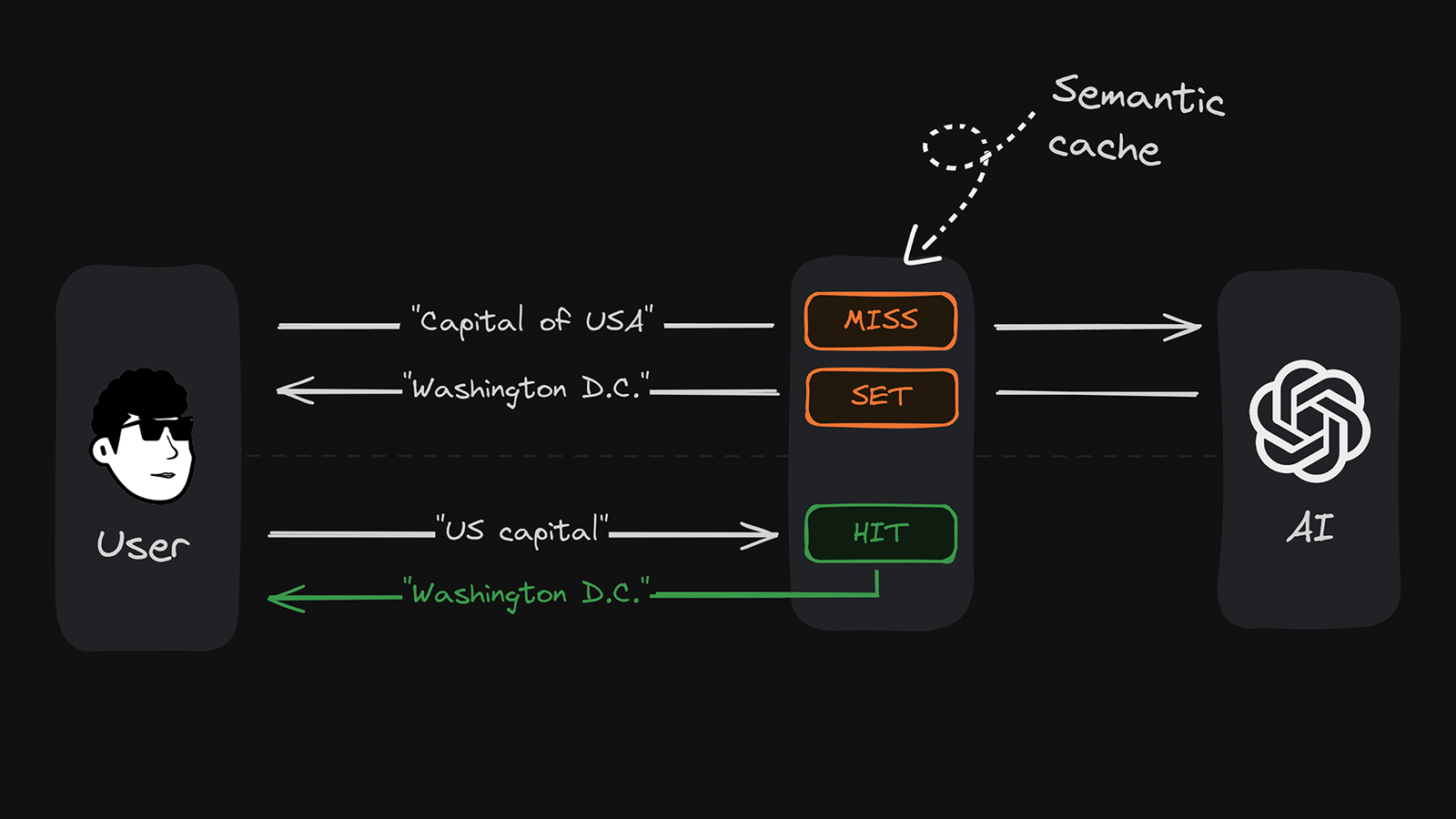
Under the hood our semantic cache leverages Upstash Vector, a performant & scalable vector database. Just to demonstrate how scalable our vector store really is, we indexed the entire Wikipedia in 11 languages just for fun a couple weeks ago.
Conclusion
Managing costs in serverless applications is important, especially with unexpected traffic spikes leading to surprise bills. In this article, we talked about four ways to reduce serverless cost:
- Redis for caching
- Workflow for background jobs & offloading API calls
- Ratelimit for controlling traffic
- Semantic Cache for optimizing AI apps
With these tools, you can optimize performance and keep costs low. Whether it's limiting requests or caching expensive responses, we help you run an efficient and cost-effective app.