
Retrieval-Augmented Generation (RAG) is an advanced framework in natural language processing that significantly enhances the capabilities of chatbots and other conversational AI systems. It merges two critical components —retrieval and generation— to deliver more accurate, contextually relevant, and informative responses.
In this blog post we will build a RAG chatbot that uses 7B model released by Mistral AI on Ollama as the LLM model, and Upstash Vector as the retriever. Both Mistral 7B on Ollama and the RAG Chatbot will be running on Fly.io.
Tech Stack
| Technology | Usage |
|---|---|
| Upstash Vector | The serverless vector database which will be used for storing vector embeddings. |
| Ollama | Platform for running LLMs on local machine. |
| Mistral 7B Model | LLM to generate chatbot response with given prompt. |
| Nomic Embedding Model | Embedding model to extract embeddings of the messages. |
| Fly.io | Platform to deploy web apps globally without having to manage complex infrastructure. |
| LangChain | Framework for developing applications powered by large language models. |
| Nextjs | The React Framework for the Web. Nextjs will be used for building the chatbot app. |
| Vercel AI SDK | Library for building AI-powered streaming text and chat UIs. |
Create Upstash Vector Database
Upstash Vector is a serverless vector database designed for working with vector embeddings. We will store the embeddings generated from messages in Upstash Vector.
We will follow the Upstash documentation to create the Vector Index that we need.
Let's login console and click to "Create Index". Creating index is pretty simple. Since the size of the embeds that our Embedding model will produce is 768, we just need to set the dimensions to 768 to make our index compatible.
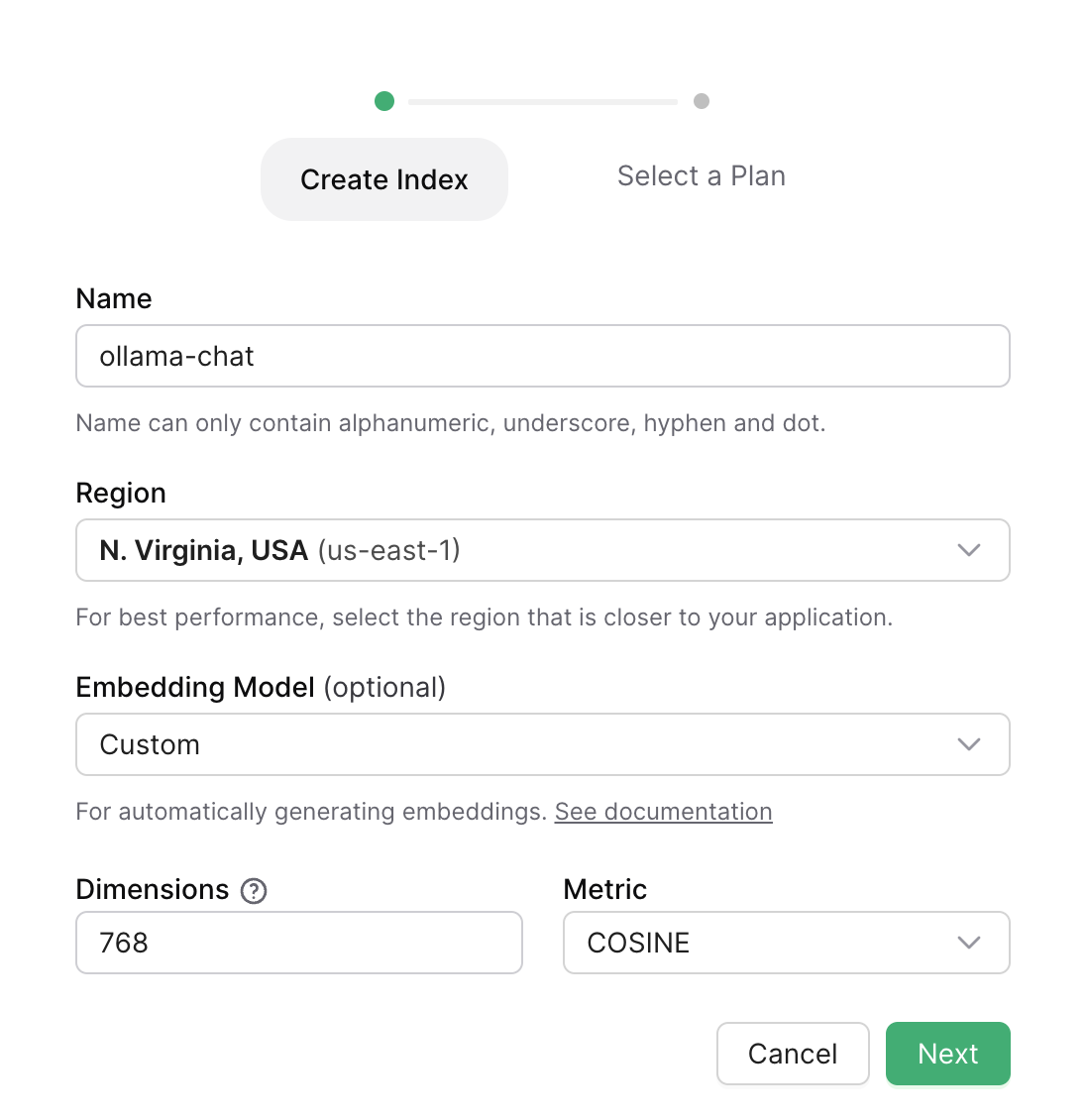
When we click "Next", we will need to select a payment plan. We can go with the free plan for this demo.
Deploy Ollama on Fly.io
Now, let's make LLM ready. We will deploy the LLM on fly.io by using Ollama.
We first need to create a fly.io account. Later on, we should setup fly.io in our local machine. To do that, we need to install flyctl, which is a command line interface to deploy projects to fly.io platform, by following the flyctl installation guide.
After installing flyctl, now we should create a fly.toml file, which will be used for deploying Ollama to fly.io. Let's create this file with the content below.
app = 'ollama-mistral'
primary_region = 'ord'
[build]
image = 'ollama/ollama'
[[mounts]]
source = 'models'
destination = '/root/.ollama'
initial_size = '100gb'
[http_service]
internal_port = 11434
auto_stop_machines = true
auto_start_machines = true
min_machines_running = 0
processes = ['app']
[[vm]]
size = 'performance-2x'To deploy Ollama by this file to fly.io, we need to open terminal, move into the directory of that file and run the following command.
fly launchThis command will open the fly.io website to complete the configuration of the deployment. On the website, the important thing for us is the VM size. It should be larger than performance-2x to be able to run LLM.
After completing the deployment, we can check if Ollama is running or not by opening the endpoint that fly.io gave, which is https://ollama-mistral.fly.dev for the demo. It should return Ollama is running string.
Now, we will add Mistral 7B model and Nomic embbeding model to Ollama. We will use Mistral 7B model as the text generator LLM, Nomic embedding model as the embed extractor. For adding these models to Ollama running on fly.io, we should run the following commands from our terminal.
curl -X POST https://ollama-noah2.fly.dev/api/pull -d '{ "model": "mistral" }'curl -X POST https://ollama-noah2.fly.dev/api/pull -d '{ "model": "nomic-embed-text" }'
These commands will pull the models and run them on the fly.io machine.
We can quickly test the models by running following commands on the terminal.
curl -X POST https://ollama-mistral.fly.dev/api/generate -d '{
"model": "mistral",
"prompt":"What is RAG?"
}'curl -X POST https://ollama-mistral.fly.dev/api/generate -d '{
"model": "nomic-embed-text",
"prompt":"What is RAG?"
}'The first command should return a text response, generated by Mistral 7B model and the second command should return the embeds of the prompted text.
Create Nextjs Application
We have our LLM ready. Now we can start working on our chatbot. Let's create a Nextjs app first.
npx create-next-app@latest mistral-chat-app
Now, we will install dependencies needed for our chatbot and its UI.
pnpm install @upstash/vector langchain @langchain/community ai zod react-toastify
We should also create .env file in the root directory of the Nextjs project to store Upstash Vector credentials and Ollama fly.io base endpoint.
To get Upstash Vector credentials, we should open Upstash Vector Console back, open the Index that we created and copy the .env configs under Connect.

Copy these configurations and paste them into the .env file in the project. Also append the following fly.io base url as well.
OLLAMA_BASE_URL="https://ollama-noah2.fly.dev"
Barebones Nextjs app for us is ready.
Implement Chatbot API
In the chatbot, we should first create POST endpoint. The input of this endpoint should be the message of the user and output should be the message generated by LLM running on Ollama.
First, we will create route.ts under app/api/chat. This file will have the POST endpoint with /api/chat extension in the url.
import { NextRequest, NextResponse } from "next/server";
import { Message as VercelChatMessage, StreamingTextResponse } from "ai";
import {Index} from "@upstash/vector";
import {OllamaEmbeddings} from "@langchain/community/embeddings/ollama";
import {ChatOllama} from "@langchain/community/chat_models/ollama";
import { PromptTemplate } from "@langchain/core/prompts";
import { UpstashVectorStore } from "@langchain/community/vectorstores/upstash";
import { Document } from "@langchain/core/documents";
import { RunnableSequence } from "@langchain/core/runnables";
import {
BytesOutputParser,
StringOutputParser,
} from "@langchain/core/output_parsers";
export const runtime = "edge";
const combineDocumentsFn = (docs: Document[]) => {
const serializedDocs = docs.map((doc) => doc.pageContent);
return serializedDocs.join("\n\n");
};
const formatVercelMessages = (chatHistory: VercelChatMessage[]) => {
const formattedDialogueTurns = chatHistory.map((message) => {
if (message.role === "user") {
return `Human: ${message.content}`;
} else if (message.role === "assistant") {
return `Assistant: ${message.content}`;
} else {
return `${message.role}: ${message.content}`;
}
});
return formattedDialogueTurns.join("\n");
};
const CONDENSE_QUESTION_TEMPLATE = `Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language.
<chat_history>
{chat_history}</chat_history>
Follow Up Input: {question}
Standalone question:`;
const condenseQuestionPrompt = PromptTemplate.fromTemplate(
CONDENSE_QUESTION_TEMPLATE,
);
const ANSWER_TEMPLATE = `You are an expert on Retrieval-Augmented Generation (RAG) chatbots, which combine retrieval-based and generation-based approaches to provide accurate and relevant information. Your goal is to provide detailed, insightful, and authoritative information about RAG chatbots, including their features, benefits, use cases, technical details, and implementation strategies. Ensure your responses are clear, concise, and helpful.
Answer the question based only on the following context and chat history:
<context>
{context}</context>
<chat_history>
{chat_history}</chat_history>
Question: {question}
`;
const answerPrompt = PromptTemplate.fromTemplate(ANSWER_TEMPLATE);
export const dynamic = 'force-dynamic';
/**
* This handler initializes and calls a retrieval chain. It composes the chain using * LangChain Expression Language. See the docs for more information: * * https://js.langchain.com/docs/guides/expression_language/cookbook#conversational-retrieval-chain */export async function POST(req: NextRequest) {
try {
const body = await req.json();
const messages = body.messages ?? [];
const previousMessages = messages.slice(0, -1);
const currentMessageContent = messages[messages.length - 1].content;
const model = new ChatOllama({
baseUrl: process.env.OLLAMA_BASE_URL as string,
model: "mistral",
temperature: 0.2,
});
const ollamaEmbeddings = new OllamaEmbeddings({
baseUrl: process.env.OLLAMA_BASE_URL as string,
model: "nomic-embed-text",
})
const indexWithCredentials = new Index({
url: process.env.UPSTASH_VECTOR_REST_URL as string,
token: process.env.UPSTASH_VECTOR_REST_TOKEN as string,
});
const vectorstore = new UpstashVectorStore(ollamaEmbeddings, {
index: indexWithCredentials,
});
/**
* We use LangChain Expression Language to compose two chains. * To learn more, see the guide here: * * https://js.langchain.com/docs/guides/expression_language/cookbook * * You can also use the "createRetrievalChain" method with a * "historyAwareRetriever" to get something prebaked. */ const standaloneQuestionChain = RunnableSequence.from([
condenseQuestionPrompt,
model,
new StringOutputParser(),
]);
let resolveWithDocuments: (value: Document[]) => void;
const documentPromise = new Promise<Document[]>((resolve) => {
resolveWithDocuments = resolve;
});
const retriever = vectorstore.asRetriever({
callbacks: [
{
handleRetrieverEnd(documents) {
resolveWithDocuments(documents);
},
},
],
});
const retrievalChain = retriever.pipe(combineDocumentsFn);
const answerChain = RunnableSequence.from([
{
context: RunnableSequence.from([
(input) => input.question,
retrievalChain,
]),
chat_history: (input) => input.chat_history,
question: (input) => input.question,
},
answerPrompt,
model,
]);
const conversationalRetrievalQAChain = RunnableSequence.from([
{
question: standaloneQuestionChain,
chat_history: (input) => input.chat_history,
},
answerChain,
new BytesOutputParser(),
]);
const stream = await conversationalRetrievalQAChain.stream({
question: currentMessageContent,
chat_history: formatVercelMessages(previousMessages),
});
const documents = await documentPromise;
const serializedSources = Buffer.from(
JSON.stringify(
documents.map((doc) => {
return {
pageContent: doc.pageContent.slice(0, 50) + "...",
metadata: doc.metadata,
};
}),
),
).toString("base64");
return new StreamingTextResponse(stream, {
headers: {
"x-message-index": (previousMessages.length + 1).toString(),
"x-sources": serializedSources,
},
});
} catch (e: any) {
return NextResponse.json({ error: e, errorMessage: e.message }, { status: e.status ?? 500 });
}
}In this file, we define the question and answer prompts. With these prompts, we give the context and the question to the LLM and expect it to answer the question given that context. We ask the LLM to be an expert on Retrieval-Augmented Generation (RAG) chatbots and give information about RAG chatbots.
After defining the prompts, we set up the ChatOllama, OllamaEmbeddings and UpstashVectorStore by using the @langchain/community. These are all implemented in Langchain community package and help us to build our chatbot API with very small effort.
We also implement this POST API with a chain to stream the output of LLM response to not block the UI while waiting the whole response.
To test the POST API quickly, we can send a request on the terminal after running the app.
> pnpm run dev
> curl -X POST https://localhost:3001/api/chat -d '{"messages":[{"role":"user","content":"What is RAG?"}]}'The output should be a stream of objects displayed in JSON format on the terminal.
Implement Chatbot UI
We have the POST endpoint ready. Now we need the UI for our chatbot. For the UI, we will use useChat of Vercel AI SDK to display the messages generated by LLM.
Let's open pages.tsx file to build our chat window. The following code will implement a very basic chatbot UI for this demo.
// File: app/page.tsx
"use client";
import { ToastContainer } from 'react-toastify';
import 'react-toastify/ReactToastify.css';
import { useChat } from "ai/react";
import { useRef, useState } from "react";
import type { FormEvent } from "react";
import { ChatMessageBubble } from "@/component/ChatMessageBubble";
export default function ChatWindow() {
const messageContainerRef = useRef<HTMLDivElement | null>(null);
const [sourcesForMessages, setSourcesForMessages] = useState<Record<string, any>>({});
const { messages, input, handleInputChange, handleSubmit} =
useChat({
api: "api/chat",
onResponse(response) {
const sourcesHeader = response.headers.get("x-sources");
const sources = sourcesHeader ? JSON.parse((Buffer.from(sourcesHeader, 'base64')).toString('utf8')) : [];
const messageIndexHeader = response.headers.get("x-message-index");
if (sources.length && messageIndexHeader !== null) {
setSourcesForMessages({...sourcesForMessages, [messageIndexHeader]: sources});
}
},
streamMode: "text",
});
async function sendMessage(e: FormEvent<HTMLFormElement>) {
e.preventDefault();
if (messageContainerRef.current) {
messageContainerRef.current.classList.add("grow");
}
if (!messages.length) {
await new Promise(resolve => setTimeout(resolve, 300));
}
handleSubmit(e);
}
return (
<div className={`flex flex-col items-center p-4 md:p-8 rounded grow overflow-hidden ${(messages.length > 0 ? "border" : "")}`}>
<h2 className={`${messages.length > 0 ? "" : "hidden"} text-2xl`}>{"Mistral Chatbot"}</h2>
<div className="flex flex-col-reverse w-full mb-4 overflow-auto transition-[flex-grow] ease-in-out"
ref={messageContainerRef}>
{[...messages]
.reverse()
.map((m, i) => {
const sourceKey = (messages.length - 1 - i).toString();
return (<ChatMessageBubble key={m.id} message={m} botName={"Bot: "} sources={sourcesForMessages[sourceKey]}></ChatMessageBubble>)
})}
</div>
<form onSubmit={sendMessage} className="flex w-full flex-col">
<div className="flex w-full mt-4">
<input
className="grow mr-8 p-4 rounded"
value={input}
placeholder={"Say something..."}
onChange={handleInputChange}/>
<button type="submit" className="shrink-0 px-8 py-4 bg-sky-600 rounded w-28 border-2 border-sky-700">
Send
</button>
</div>
</form>
<ToastContainer/>
</div>
);
}Vercel AI SDK makes the streaming for chat apps very easy.
The file above was the ChatWindow of the Chatbot, which displays messages in message bubbles. Now we need Chat message bubbles. The following Typescript file will be very basic message bubble.
// File: app/component/ChatMessageBubble.tsx
import type { Message } from "ai/react";
export function ChatMessageBubble(props: { message: Message, botName?: string, sources: any[] }) {
const colorClassName = props.message.role === "user" ? "bg-sky-600" : "bg-slate-50 text-black";
const alignmentClassName = props.message.role === "user" ? "ml-auto" : "mr-auto";
const prefix = props.message.role === "user" ? "User:" : props.botName;
return (
<div className={`${alignmentClassName} ${colorClassName} rounded px-4 py-2 max-w-[80%] mb-8 flex`}>
<div className="mr-2">
{prefix}
</div>
<div className="whitespace-pre-wrap flex flex-col">
<span>{props.message.content}</span>
{props.sources && props.sources.length ? <>
<code className="mt-4 mr-auto bg-slate-600 px-2 py-1 rounded">
<h2>
Sources:
</h2>
</code>
<code className="mt-1 mr-2 bg-slate-600 px-2 py-1 rounded text-xs">
{props.sources?.map((source, i) => (
<div className="mt-2" key={"source:" + i}>
{i + 1}. "{source.pageContent}"{
source.metadata?.loc?.lines !== undefined
? <div><br/>Lines {source.metadata?.loc?.lines?.from} to {source.metadata?.loc?.lines?.to}</div>
: ""}
</div>
))}
</code>
</> : ""}
</div>
</div>
);
}Our chatbot application is ready! We can test it by openning localhost:3001 on any browser.

Deploy the Chatbot to Fly.io
Finally, we will deploy the chatbot to fly.io, as we did for Ollama.
flyctl cli can recognize if the project is Nextjs. Therefore, we only need to run the same command that we run to deploy Ollama.
Let's open the terminal again, move into the root directory of the project and run the following command.
fly launch
Again, this command will open the fly.io website for further configuration of the deployment. We can use the default machine size for this demo project.
After the deployment completed, we can reach to the RAG chatbot from the URL given by fly.io. In this demo project, it will be https://mistral-chat-app.fly.dev.
Conclusion
At the end of this blog post, we have two apps running on fly.io.
The first one is Ollama, which runs Mistral 7B LLM model to generate responses to given questions in particular context and Nomic Embeddings model to extract embeddings of given text input.
The second one is the RAG Chatbot, which is an application written in Next.js using the Vercel AI SDK and Langchain. This application interacts with Ollama running on fly.io to generate text from Mistral 7B model. The app also interacts with Upstash Vector to store the embeddings and retrieve from the vector index.
The project implemented in this blog post is just a proof of concept. It has a very basic UI and very small amount of resources. The project can be much improved by developing a better UI and adding more resources to make the app perform better.